Custom Web Scraping Playbook Using Python
Tools used
Download playbook
By clicking download you subscribe to our marketing communications.

How it works
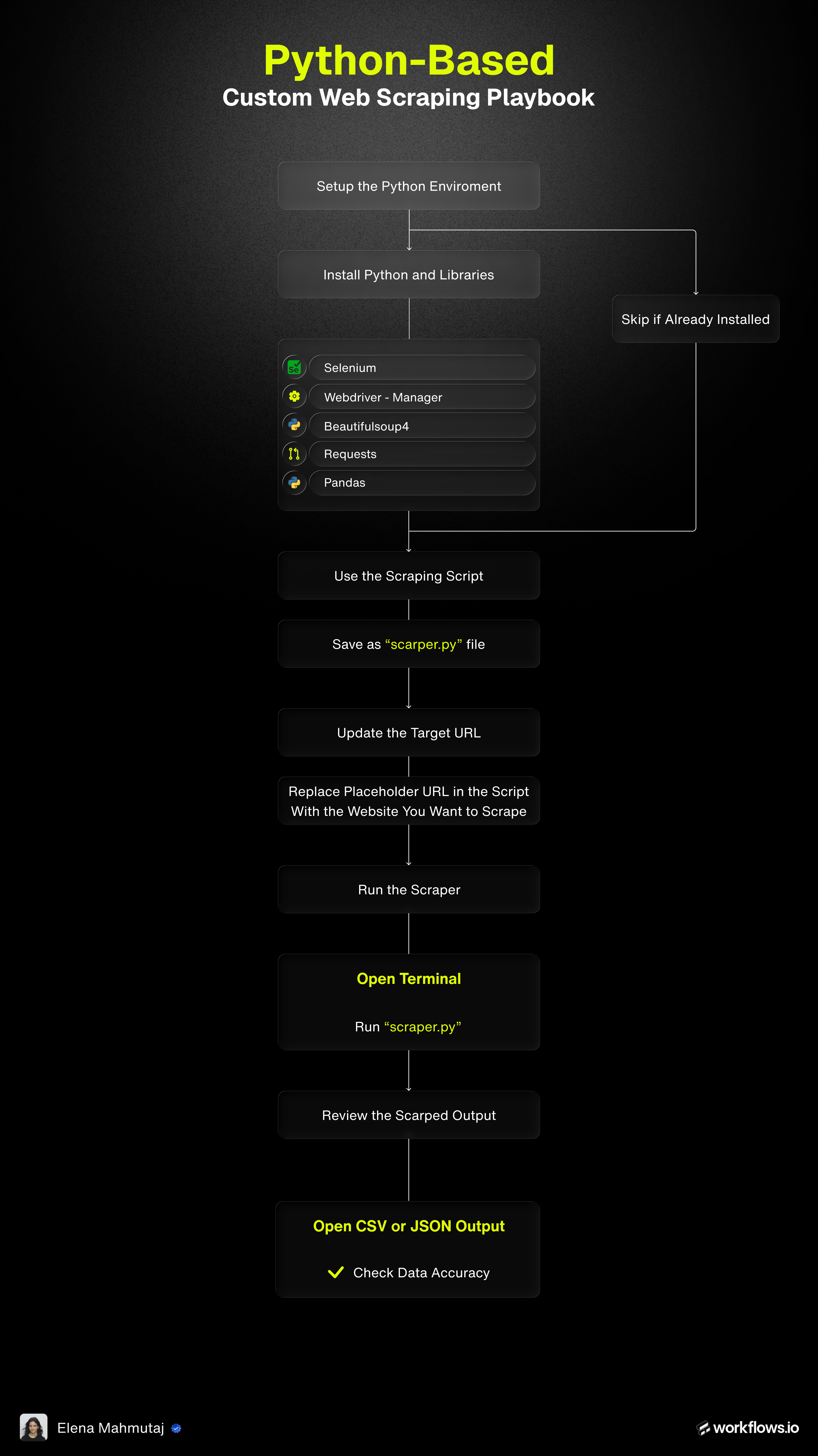
Step 1: Set up the python environment
Step 2: Save the scraping script locally
Step 3: Configure the target website
Step 4: Run the scraper
Step 5: Review the scraped output
Step 6: Customize scraping logic as needed (Optional)
Step 7: Handle failures and iterate (Optional)
Share
Scroll to zoom in and out, drag to navigateUse 2 fingers to drag, zoom in and out